
MemSpark:一个面向 Windows 的轻量级内存优化工具
前言
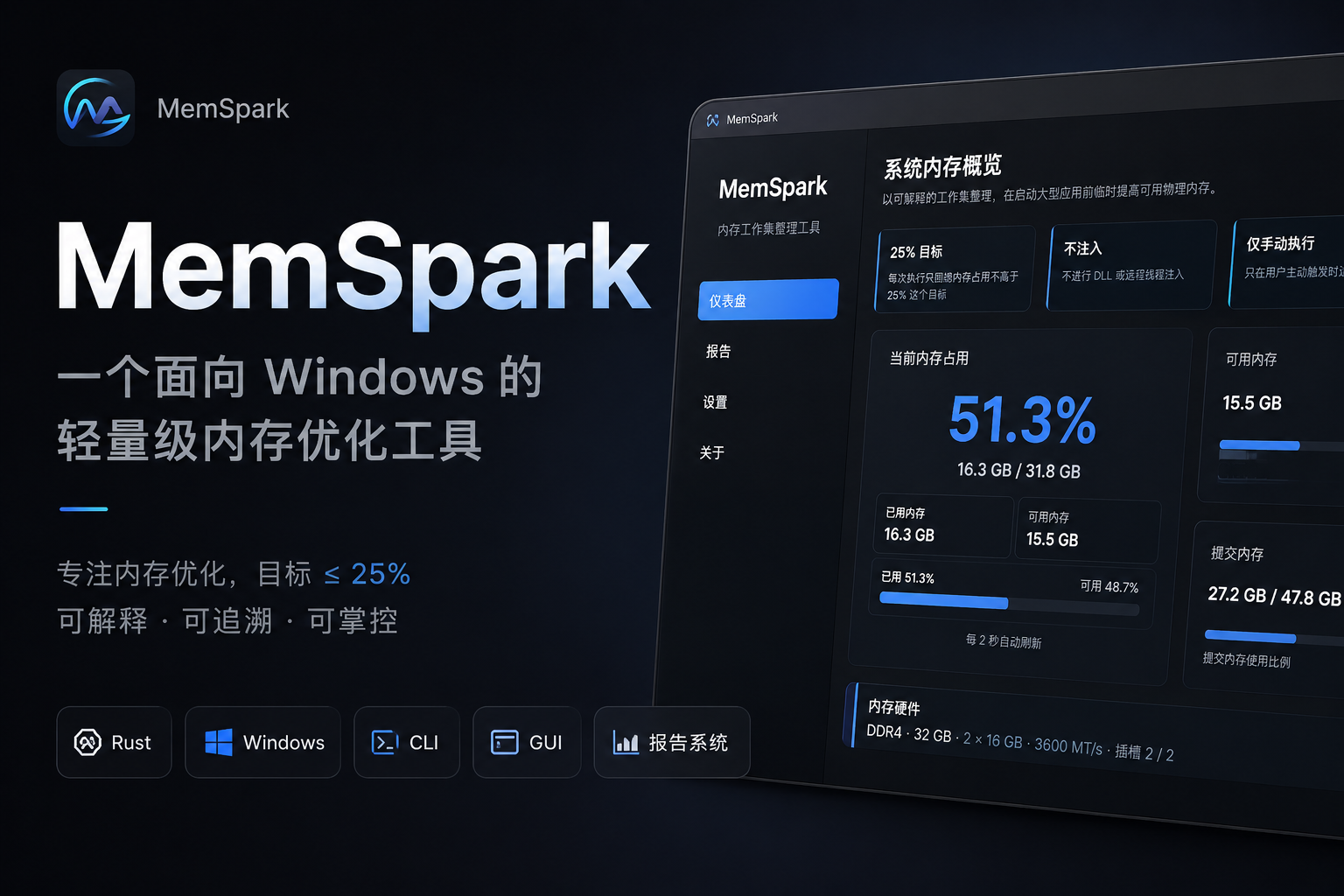
MemSpark 是一个面向 Windows 的轻量级内存优化工具。它的定位很明确:只保留一个入口,即“内存优化”,并围绕一个目标工作,尽量把当前内存占用压低到 25% 或以下。
这不是一个常驻后台清理器,也不是“系统加速大师”。MemSpark 更适合在启动大型应用、游戏、开发工具、虚拟机或浏览器重负载场景前手动执行一次。它会读取当前系统内存状态,整理可处理进程的工作集,执行系统级内存释放,并在优化结束后生成报告。
项目地址:
为什么做这个工具
Windows 的内存管理本身已经很成熟。很多时候,任务管理器里的“已用内存”并不代表内存真的被浪费了,系统缓存、Standby List、进程工作集都可能在需要时被系统回收。
但在一些具体场景里,用户仍然会希望临时整理一次内存:
启动大型游戏前,希望减少后台进程占用。
打开大型 IDE、渲染软件或虚拟机前,希望释放更多可用物理内存。
浏览器、聊天软件、开发工具长期运行后,希望手动整理工作集。
想知道一次优化到底处理了哪些进程、释放了多少、失败在哪里。
所以 MemSpark 没有做一堆模式,也没有做复杂的定时任务。当前版本只保留一个动作:用户手动点击或执行命令后进行一次内存优化。
功能概览
MemSpark v0.1.4 当前包含 GUI 和 CLI 两种使用方式。
GUI 版本适合直接双击使用:
Dashboard:查看当前物理内存、可用内存、系统缓存、提交内存和进程数量。
Report:查看最近一次优化报告。
Settings:切换语言和主题,打开报告目录,清理历史报告和开发者日志。
About:查看版本、许可和安全边界。
CLI 版本适合脚本、终端和调试:
.\MemSpark-CLI-v0.1.4-windows-x64.exe status
.\MemSpark-CLI-v0.1.4-windows-x64.exe trim --dry-run
.\MemSpark-CLI-v0.1.4-windows-x64.exe trim --dry-run --verbose
.\MemSpark-CLI-v0.1.4-windows-x64.exe trim
.\MemSpark-CLI-v0.1.4-windows-x64.exe report last其中 trim --dry-run 不会真正释放内存,只用于预览候选进程和跳过原因。
技术栈
MemSpark 使用 Rust 开发,采用 Cargo workspace 拆分为三个 crate:
crates/memspark-core 核心逻辑、Windows API 边界、报告和配置
crates/memspark-cli 命令行入口
crates/memspark-ui Slint 图形界面主要依赖包括:
windows-sys:调用 Windows API。slint:构建 GUI。clap:解析 CLI 命令。serde/serde_json/toml:配置和报告序列化。thiserror:错误类型管理。
这种拆分的好处是:GUI 和 CLI 不各写一套优化逻辑,而是共同调用 memspark-core。Windows API 相关的不安全边界也集中在 core 层里,方便审查和维护。
核心流程
MemSpark 的核心优化入口在 memspark-core 中。流程大致是:
读取优化前内存快照。
加载配置和策略。
非 dry-run 模式下尝试启用相关权限。
枚举进程并整理候选进程工作集。
执行系统级内存释放。
读取优化后内存快照。
统计扫描、处理、跳过和失败数量。
生成优化报告。
核心代码结构如下:
pub fn optimize(dry_run: bool, config: &AppConfig) -> Result<OptimizeReport> {
let started = Instant::now();
let before = get_memory_snapshot()?;
let policy = config.policy().clone();
let options = trim_options(&policy);
if !dry_run {
let _ = winapi::enable_debug_privilege();
let _ = winapi::enable_increase_quota_privilege();
let _ = winapi::enable_profile_privilege();
}
let trim_report = trim_working_sets_aggressive(options, dry_run)?;
let system_cleanup = run_memory_optimization_target_cleanup(dry_run);
let after = get_memory_snapshot().unwrap_or_else(|_| before.clone());
Ok(OptimizeReport {
mode: OptimizeMode::MemoryOptimization,
dry_run,
timestamp_unix: SystemTime::now()
.duration_since(UNIX_EPOCH)
.unwrap_or_default()
.as_secs(),
duration_ms: started.elapsed().as_millis() as u64,
before,
after,
scanned_count,
trimmed_count,
skipped_count,
failed_count,
effect,
results: trim_report.results,
})
}这里没有把“释放了多少内存”写死成一个理论值,而是通过优化前后的快照差异计算报告。因为 Windows 内存状态会受到内核、驱动、系统缓存、前台进程、不可终止进程和硬件保留等因素影响,最终结果必须以实际快照为准。
Windows API 边界
MemSpark 的内存状态读取依赖 GlobalMemoryStatusEx 和 GetPerformanceInfo。这两个 API 分别用于读取物理内存、可用内存、提交内存、系统缓存等数据。
pub fn memory_snapshot() -> Result<MemorySnapshot> {
unsafe {
let mut memory: MEMORYSTATUSEX = zeroed();
memory.dwLength = size_of::<MEMORYSTATUSEX>() as u32;
if GlobalMemoryStatusEx(&mut memory) == 0 {
return Err(MemSparkError::WinApi(
last_error("GlobalMemoryStatusEx").to_string(),
));
}
let mut perf: PERFORMANCE_INFORMATION = zeroed();
perf.cb = size_of::<PERFORMANCE_INFORMATION>() as u32;
if GetPerformanceInfo(&mut perf, size_of::<PERFORMANCE_INFORMATION>() as u32) == 0 {
return Err(MemSparkError::WinApi(
last_error("GetPerformanceInfo").to_string(),
));
}
// 后续将 Windows 原始数据转换为 MemorySnapshot。
}
}进程工作集整理使用 Windows 提供的工作集相关 API。失败时会记录原因,不会把错误吞掉后假装成功。
if SetProcessWorkingSetSizeEx(handle.0, usize::MAX, usize::MAX, 0) == 0 {
return Err(last_error("SetProcessWorkingSetSizeEx"));
}系统级释放部分会通过 NtSetSystemInformation(SystemMemoryListInformation) 请求 Windows 处理系统工作集、Modified Page List 和 Standby List。
pub fn set_system_memory_list(
command: MemoryListCommand,
) -> std::result::Result<(), WinApiError> {
let mut command = memory_list_command_value(command);
let status = unsafe {
NtSetSystemInformation(
SYSTEM_MEMORY_LIST_INFORMATION,
&mut command as *mut i32 as *mut c_void,
size_of::<i32>() as u32,
)
};
if status == STATUS_SUCCESS {
Ok(())
} else {
Err(ntstatus_error(
"NtSetSystemInformation(SystemMemoryListInformation)",
status,
))
}
}这些操作往往需要管理员权限。MemSpark 的 GUI 和 CLI 都会在需要时请求提权。
单一模式策略
早期内存工具常见的问题是模式过多:普通、强力、深度、极限、游戏模式、自动模式。模式越多,用户越难判断到底该点哪个,也更容易把危险行为包装成“高级功能”。
MemSpark 当前只保留一个模式:
#[derive(Debug, Clone, Copy, PartialEq, Eq, Serialize, Deserialize)]
#[serde(rename_all = "lowercase")]
pub enum OptimizeMode {
#[serde(rename = "memory_optimization", alias = "normal", alias = "strong")]
MemoryOptimization,
}旧名称 normal、strong 只作为兼容别名存在,真实显示名称就是“内存优化”。这使得 GUI 和 CLI 都围绕同一个行为约束展开:手动触发、可解释、有报告、有边界。
报告和日志
MemSpark 不只执行优化,还会保存结果。
默认路径:
%APPDATA%\MemSpark\last_report.json
%APPDATA%\MemSpark\history
%APPDATA%\MemSpark\logs保存最近一次报告前,会先把旧报告归档到历史目录:
archive_existing_report(config, &path)?;
let content = serde_json::to_string_pretty(report)?;
fs::write(&path, content)?;开发者日志单独保存,包含更详细的执行信息:
pub fn save_developer_log(config: &AppConfig, report: &OptimizeReport) -> Result<Option<PathBuf>> {
let log_dir = developer_log_dir(config);
fs::create_dir_all(&log_dir)?;
let path = unique_developer_log_path(&log_dir, report.timestamp_unix);
fs::write(&path, format_developer_log(report)?)?;
Ok(Some(path))
}这样做的原因很简单:内存优化这类工具不能只告诉用户“成功了”。它需要告诉用户:
优化前后内存占用是多少。
可用内存变化是多少。
扫描了多少进程。
处理了多少进程。
跳过了多少进程。
哪些步骤失败了。
系统级释放是否成功。
这些信息比一个模糊的“释放成功”更有价值。
CLI 如何处理提权
CLI 在非 dry-run 模式下,如果当前不是管理员进程,会重新以管理员权限启动自身,并通过临时 JSON 文件把提权子进程的报告传回普通进程。
fn trim(config_path: Option<PathBuf>, args: TrimArgs) -> Result<(), MemSparkError> {
let config = load_config_or_default(config_path.as_deref())?;
if !args.dry_run && !args.elevated_child && !is_running_as_admin() {
return run_elevated_trim(config_path, args);
}
let report = optimize(args.dry_run, &config)?;
println!("{}", format_report_text_with_options(&report, args.verbose));
save_report_artifacts(&config, &report);
Ok(())
}这种方式避免了 GUI 或 CLI 依赖外部辅助程序。单文件 GUI 可以自己完成提权子进程调用,不需要同目录额外放置 CLI 可执行文件。
GUI 设计
GUI 使用 Slint 构建。界面重点不是装饰,而是清楚地呈现当前状态和优化结果。
优化过程运行在线程中,执行期间界面继续刷新内存占用率。优化完成后,GUI 会把报告数据写入 Report 页面:
fn apply_report_view_data(app: &AppWindow, data: ReportViewData) {
app.set_report_text(data.text.into());
app.set_report_before_memory_text(data.before_memory.into());
app.set_report_after_memory_text(data.after_memory.into());
app.set_report_available_increase_text(data.available_increase.into());
app.set_report_scanned_text(data.scanned.into());
app.set_report_trimmed_text(data.trimmed.into());
app.set_report_skipped_text(data.skipped.into());
app.set_report_failed_text(data.failed.into());
}GUI 还支持深色和浅色主题、中英文界面、报告目录打开、历史报告清理和开发者日志清理。
安全边界
MemSpark 的边界是:
不进行 DLL 注入。
不进行远程线程注入。
不修改其他进程内存数据。
不删除用户数据。
默认跳过系统关键进程、前台进程和自身进程。
需要注意的是,为了推进 25% 目标,MemSpark 可能处理非系统后台候选进程。被处理的进程如果存在未保存数据,仍然可能带来数据丢失风险。因此它不做后台自动定时清理,而是保留手动触发。
构建和验证
开发验证命令:
cargo fmt --all -- --check
cargo clippy --workspace --all-targets
cargo test
cargo build --release发布包包含:
MemSpark-GUI-v0.1.4-windows-x64.exe
MemSpark-CLI-v0.1.4-windows-x64.exe
MemSpark-v0.1.4-windows-x64.zip小结
MemSpark 的核心思路不是“让系统永远更快”,而是提供一次可解释、可追溯、手动触发的内存整理流程。
适合那些希望在特定场景前临时整理内存的用户,也适合开发者观察 Windows 工作集、系统缓存、报告数据和提权流程。工具本身保持轻量,行为边界清楚,结果通过报告呈现,而不是只给用户一个无法验证的成功提示。