
Bugku CTF系列: Where is flag Plus攻略
题目地址:
一、获取并分析
下载附件后我们得到如下内容:
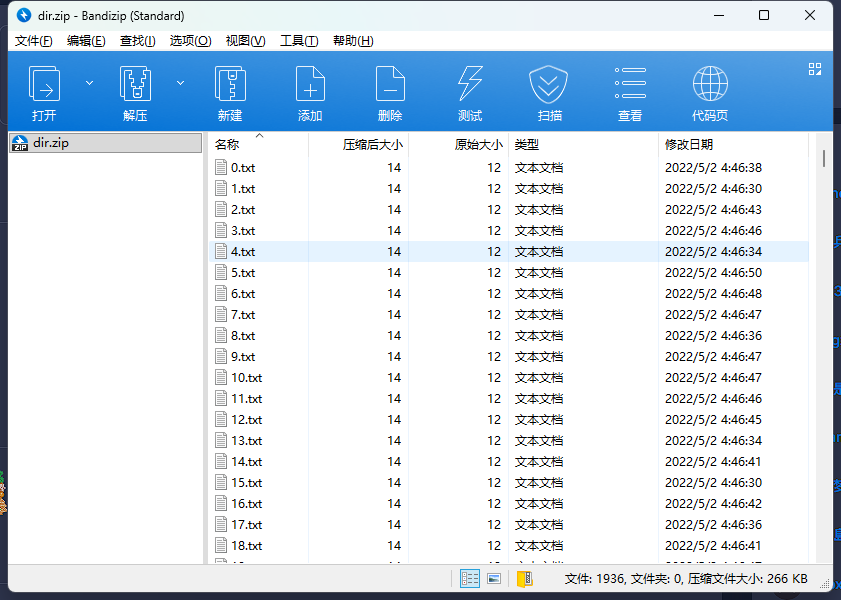
压缩包中存在很多txt文档,其中的内容很像是base编码,但是尝试了base家族所有的解码都是乱码,最后我去看了看别人的思路发现答案其实就在眼前,那就是文件的修改时间,时间都在30秒到50秒之间,通过判断时间得出二进制在转为十六进制复原文件。
二、解题
编程思路:
首先定义工作路径和工作对象
循环文件总数 0-1935(1936)
然后获取文件修改时间
对比秒数大于等于40记为1,反之为0
记满8位二进制数后转为十六进制并记入新变量
清空二进制变量,开始新循环
循环结束后,打印新变量
将结果保存为7z压缩文件即可得到新文件
代码实现:
# ctf_check.py
import os, time, string, sys
from pathlib import Path
WORK_DIR = r'CTF\files' # ← 改成你的目录(不要以 / 结尾也可以)
OUT_PREFIX = Path(WORK_DIR) / "result_variant"
def build_hex_from_mtime():
flag = ''
out = ''
for i in range(1936):
path = os.path.join(WORK_DIR, f"{i}.txt")
if not os.path.exists(path):
raise FileNotFoundError(f"缺少文件: {path}")
file_time = os.path.getmtime(path)
s = time.ctime(file_time)
sec = int(s[17:19]) # 和你原来逻辑一致
flag += '1' if sec >= 40 else '0'
if len(flag) == 8:
out += hex(int('0b' + flag, 2))[2:].zfill(2)
flag = ''
return out
def is_clean_hex(h):
h2 = h.strip()
return len(h2) % 2 == 0 and all(c in string.hexdigits for c in h2)
def hex_to_bitstr(h):
return ''.join(f"{int(h[i:i+2],16):08b}" for i in range(0,len(h),2))
def bitstr_to_hex(bs):
return ''.join(hex(int(bs[i:i+8],2))[2:].zfill(2) for i in range(0,len(bs),8))
def write_bytes_from_hex(h, outpath):
data = bytes.fromhex(h)
outpath.write_bytes(data)
return data
def try_py7zr_extract(path, extract_to):
try:
import py7zr
except Exception as e:
return False, f"py7zr 未安装或导入失败: {e}"
try:
with py7zr.SevenZipFile(path, mode='r') as zf:
zf.extractall(path=extract_to)
return True, "OK"
except Exception as e:
return False, f"py7zr 解压失败: {e}"
def main():
print("[*] 生成十六进制串 ...")
out = build_hex_from_mtime()
print(f"[*] 生成 hex 长度: {len(out)} chars, bytes: {len(out)//2}")
if not is_clean_hex(out):
print("[!] 十六进制串包含非法字符或长度为奇数。请打印查看 out 内容。")
print(out[:2000])
return
# 基本检查
header = out[:8].upper()
print("[*] 前8字符 (4 bytes) :", header)
# 7z signature = 37 7A BC AF -> '377ABCAF'
if header == '377ABCAF':
print("[+] 看起来已包含 7z 文件头,直接写入 result.ok.7z")
dst = Path(WORK_DIR) / "result.ok.7z"
data = write_bytes_from_hex(out, dst)
print(f"[+] 写入 {dst} (size {len(data)} bytes). 尝试用 py7zr 解压 ...")
ok, msg = try_py7zr_extract(dst, Path(WORK_DIR)/"extracted_ok")
print("->", ok, msg)
return
print("[*] 未检测到标准 7z 文件头 (377ABCAF)。开始尝试常见位/字节变换 ...")
bitstr = hex_to_bitstr(out)
variants = []
# Variant A: 原样(msb-first per byte)
variants.append(("orig", out))
# Variant B: 每字节内部反转位(例如 0bABCDEFGH -> HGFEDCBA)
bs_b = ''.join(bitstr[i:i+8][::-1] for i in range(0, len(bitstr), 8))
variants.append(("bits_reversed_in_each_byte", bitstr_to_hex(bs_b)))
# Variant C: 反转字节序(最后一个字节变为第一个)
bytes_list = [out[i:i+2] for i in range(0, len(out), 2)]
bytes_rev = ''.join(reversed(bytes_list))
variants.append(("bytes_reversed_order", bytes_rev))
# Variant D: bytes order reversed + bits reversed in each byte
# do bits reverse on bytes_rev
bs_from_bytes_rev = hex_to_bitstr(bytes_rev)
bs_d = ''.join(bs_from_bytes_rev[i:i+8][::-1] for i in range(0, len(bs_from_bytes_rev), 8))
variants.append(("bytes_reversed_and_bits_reversed_in_each_byte", bitstr_to_hex(bs_d)))
# Variant E: 全位反转(把整个位串反过来,然后按 8 位分组)
bs_e = bitstr[::-1]
variants.append(("all_bits_reversed_then_group", bitstr_to_hex(bs_e)))
# 试写每个变体并检查 7z header +(若可用)尝试 py7zr 解压
found = False
for idx, (name, hexstr) in enumerate(variants, start=1):
p = Path(WORK_DIR) / f"result_variant_{idx}_{name}.7z"
try:
data = write_bytes_from_hex(hexstr, p)
except Exception as e:
print(f"[!] 写入 {p} 失败: {e}")
continue
print(f"[>] 写入 {p} (size {len(data)} bytes); header: {data[:4].hex().upper()}")
if data[:4] == bytes.fromhex("377ABCAF"):
print(f"[+] 变换 {name} 命中 7z signature (377ABCAF)。尝试用 py7zr 解压 ...")
ok, msg = try_py7zr_extract(p, Path(WORK_DIR)/f"extracted_{idx}_{name}")
print("->", ok, msg)
if ok:
# 复制为最终成功文件
final = Path(WORK_DIR) / "result.ok.7z"
final.write_bytes(data)
print(f"[+] 已生成 result.ok.7z 并解压到 extracted_{idx}_{name},请查看 snow.txt")
found = True
break
else:
print(f" header mismatch: {data[:4].hex().upper()} != 377ABCAF")
if not found:
print("[!] 尝试完所有常见变换后仍未找到有效 7z header。")
print("建议:")
print(" 1) 检查 out 是否确实包含 1936 bit (即 len(out)//2 应 = 242 bytes)。")
print(" 2) 如果你手动 copy/paste 过 hex,可能粘贴时丢了字符或加入了换行。确保直接用脚本生成并用 bytes.fromhex 写入。")
print(" 3) 如果你想我继续深挖,可以把(或打印)前 64 个 hex 字节给我,我帮你看 header/签名。")
else:
print("[*] 成功结束。")
if __name__ == '__main__':
main()将压缩包解压后得到新文件snow.txt,文件内容如下:
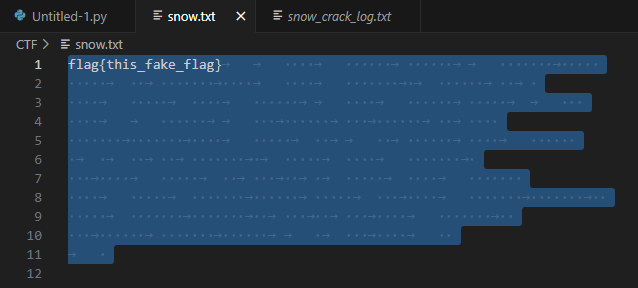
发现文件中有许多空格和缩进等不可见内容,再看文件名称是snow,这是一种隐写方式:
Snow 是一种隐写工具,通过在文本文件末尾追加由制表位隔开的空格来实现数据隐藏。最多可以添加7个空格,这使得每8列可以嵌入3位数据。
我们在官网下载Snow工具:
下载好后将文件拖到需要的工具文件夹中,该加密方式解密需要密码,而我们并没有,所以只能通过字典爆破解决,打开我们的vsc。
编程思路:
导入字典文件
循环取出文件中的密码
调用Snow.exe填充密码并指定解密对象
代码实现:
import os
with open("./CTF/rockyou.txt", "r", encoding="latin-1") as f:
for line in f.read().splitlines():
out = os.system('C:\AppSoftInstall\SNOW.EXE -p "{}" -C ./CTF/snow.txt'.format(line))三、结果
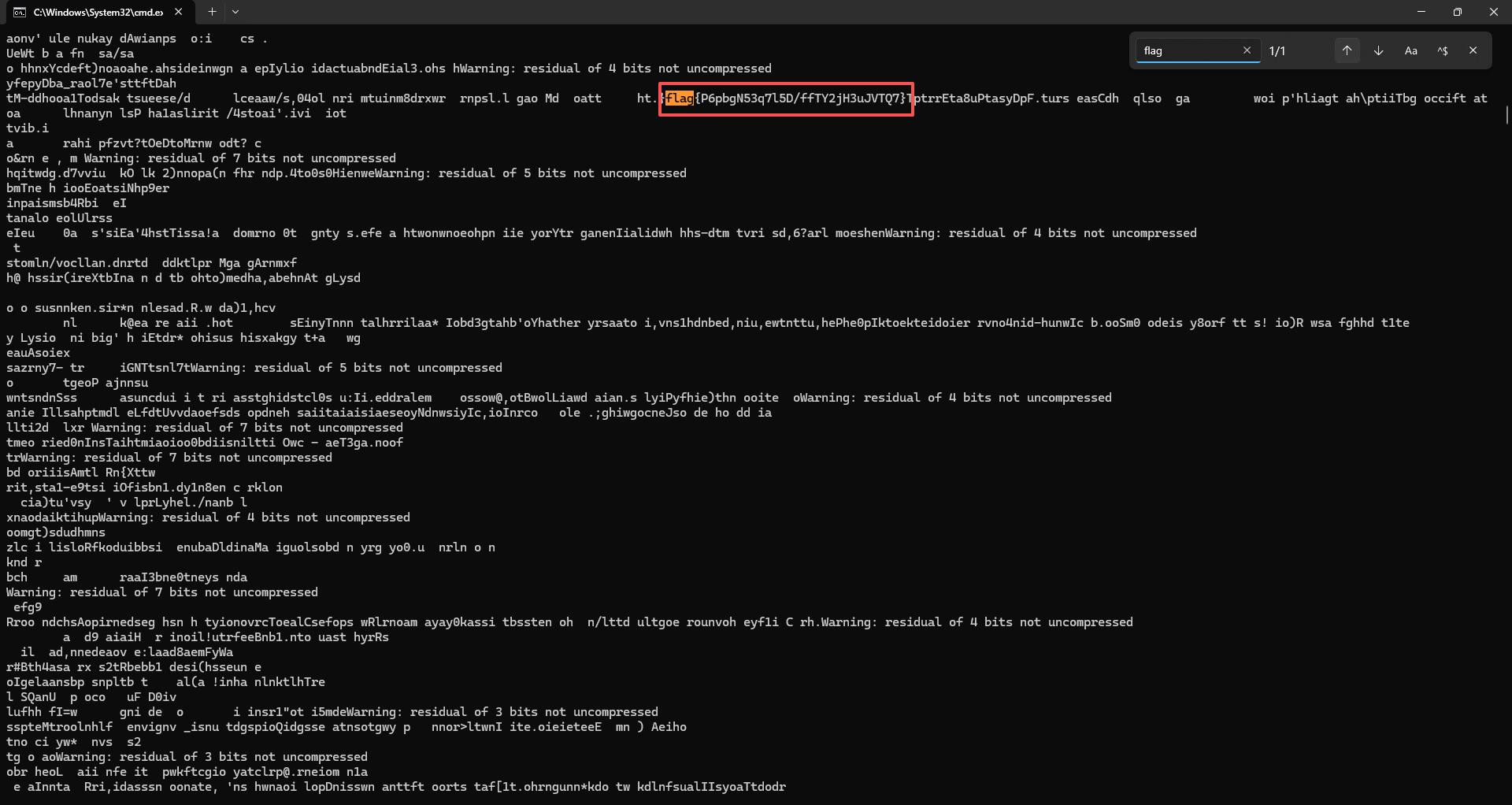
在运行一段时间后(1-2分钟左右)中断运行,Ctrl + F 查找关键词 flag即可获得如下结果:
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 Vincent Cassano