
Labelme 图像标注 学习笔记
前置步骤
安装Anaconda软件工具
使用打开 Win+R 打开 CMD创建虚拟环境
# 创建虚拟环境
# conda create -n [虚拟环境] python=[版本]
conda create -n labelme python=3.10
# 激活虚拟环境
conda activate labelme
# 下载Labelme和所需依赖环境
pip install PyQt5 pillow labelme==3.16.2 -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
# 启动Labelme工具
labelme工具中各功能中文介绍
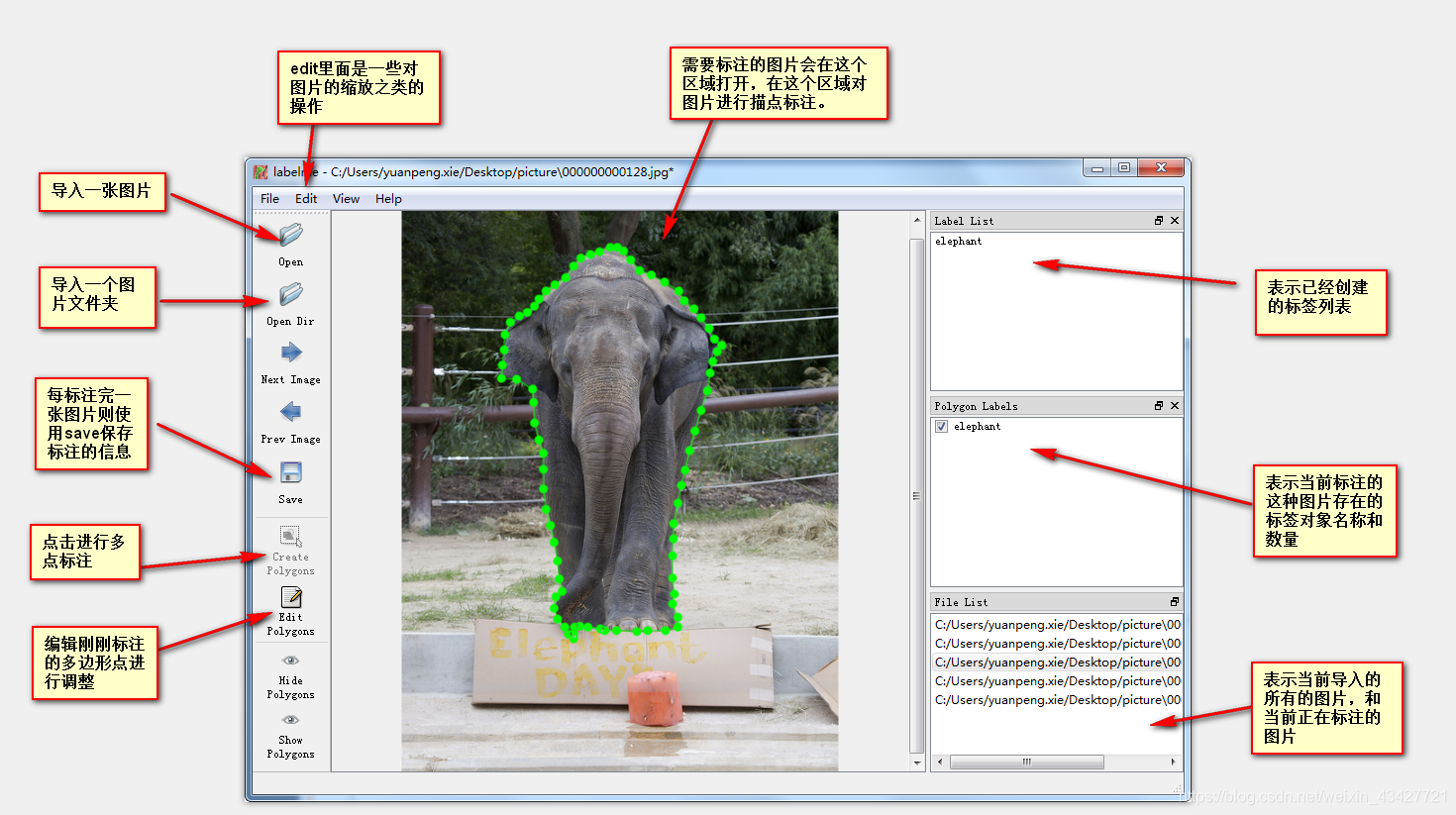
编辑菜单功能翻译:
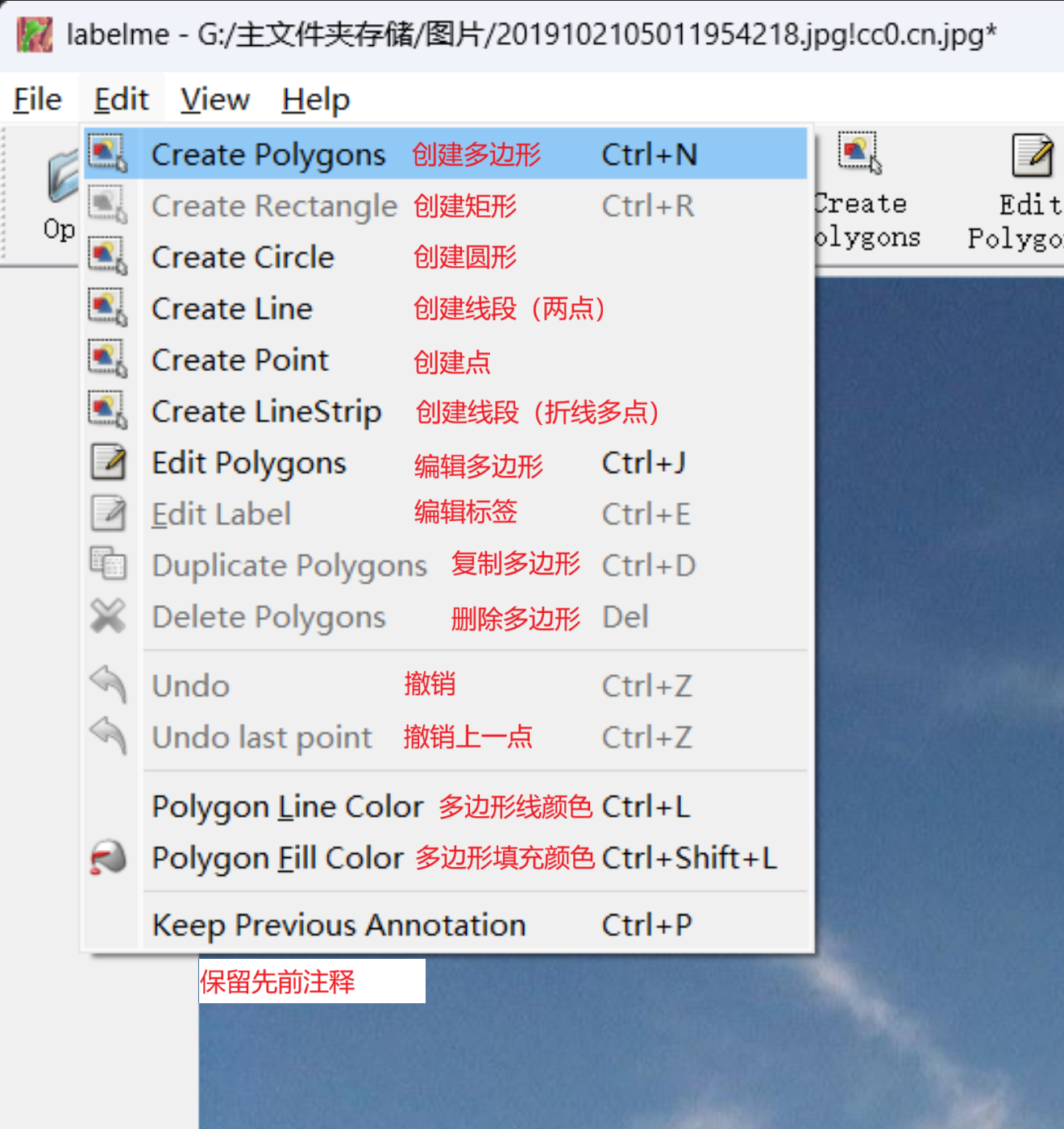
点击 Open 打开一张图片,然后按住 Ctrl + R 使用矩形标注编辑
选中起始点,然后再次点击结束点,框选完成。
随后会跳出小弹窗,在其中输入标签名称(最好使用英文名称或是拼音),描述选填
点击 OK ,这样标注就完成了。
在使用过程中建议大家一打开文件(OpenDir)的方式读取图片,这样可以通过 NextImage 和 PreImage 键来查看前后的图片。
标注完之后点击 save 进行保存,注意:最好把标注完的json文件与原图存放在一个目录下,这样在后期查看的时候可以看到原图与标注区域的叠加,而不单单是原图。
得到 json 文件之后,我们要将其转化成数据集使用,这里涉及到 Labelme 源码的更改
由于原始脚本只提供处理单个 JSON 文件的功能,所以需要对其进行修改,以实现批量处理功能
使用Everything工具搜索 json_to_dataset.py,将此文件复制一份 json_to_dataset.py.bak,再将源文件移动至项目工作区下
随后打开 json_to_dataset.py将代码做如下更改:
import argparse
import os
import os.path as osp
import warnings
import json
import base64
import PIL.Image
import yaml
from labelme import utils
def process_json(json_path, out_root=None):
"""
将单个 JSON 文件转换为图像 + 标签 + 可视化图 + label_names.txt + info.yaml
"""
with open(json_path, 'r', encoding='utf-8') as f:
data = json.load(f)
# 获取图像数据
imageData = data.get('imageData')
if not imageData:
imagePath = osp.join(osp.dirname(json_path), data['imagePath'])
with open(imagePath, 'rb') as f_img:
imageData = f_img.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
# 构建 label_name -> value 映射
label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name not in label_name_to_value:
label_name_to_value[label_name] = len(label_name_to_value)
# 检查 label 是否连续
label_values = list(label_name_to_value.values())
assert label_values == list(range(len(label_values))), \
f"Label values not continuous: {label_values}"
# 生成 label 图
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
# 生成可视化标签图
captions = [f'{v}: {n}' for n, v in sorted(label_name_to_value.items(), key=lambda x: x[1])]
lbl_viz = utils.draw_label(lbl, img, captions)
# 输出目录
if out_root is None:
out_dir = osp.join(osp.dirname(json_path), osp.basename(json_path).replace('.', '_'))
else:
out_dir = osp.join(out_root, osp.basename(json_path).replace('.', '_'))
os.makedirs(out_dir, exist_ok=True)
# 保存文件
PIL.Image.fromarray(img).save(osp.join(out_dir, 'img.png'))
utils.lblsave(osp.join(out_dir, 'label.png'), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, 'label_viz.png'))
# 保存 label_names.txt
label_names = [None] * (max(label_name_to_value.values()) + 1)
for name, value in label_name_to_value.items():
label_names[value] = name
with open(osp.join(out_dir, 'label_names.txt'), 'w', encoding='utf-8') as f:
for lbl_name in label_names:
f.write(lbl_name + '\n')
# 保存 info.yaml(保留兼容性)
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=label_names)
with open(osp.join(out_dir, 'info.yaml'), 'w', encoding='utf-8') as f:
yaml.safe_dump(info, f, default_flow_style=False)
print(f'Saved to: {out_dir}')
def main():
warnings.warn("This script converts a folder of JSON files to images and labels.\n"
"It demonstrates dataset preparation from LabelMe JSON files.")
parser = argparse.ArgumentParser()
parser.add_argument('json_path', help='单个 JSON 文件或 JSON 文件夹')
parser.add_argument('-o', '--out', default=None, help='输出根目录(可选)')
args = parser.parse_args()
# 判断输入是文件还是文件夹
if osp.isfile(args.json_path):
process_json(args.json_path, out_root=args.out)
elif osp.isdir(args.json_path):
json_files = [f for f in os.listdir(args.json_path) if f.lower().endswith('.json')]
if not json_files:
print("No JSON files found in the directory.")
return
for json_file in json_files:
process_json(osp.join(args.json_path, json_file), out_root=args.out)
else:
print("Input path does not exist.")
if __name__ == '__main__':
main()
将之前标注好的json文件都复制一份提取出来,放在一个新的目录下,然后进入我们批量处理程序
# 处理单独的JSON文件
python -m labelme.examples.dataset_tool.json_to_dataset [文件名].json
# 处理批量的JSON文件
python -m labelme.examples.dataset_tool.json_to_dataset [目录名]
# 指定输出目录 -o OUTPUT_DIR
python -m labelme.examples.dataset_tool.json_to_dataset [输入目录名] -o [输出目录名]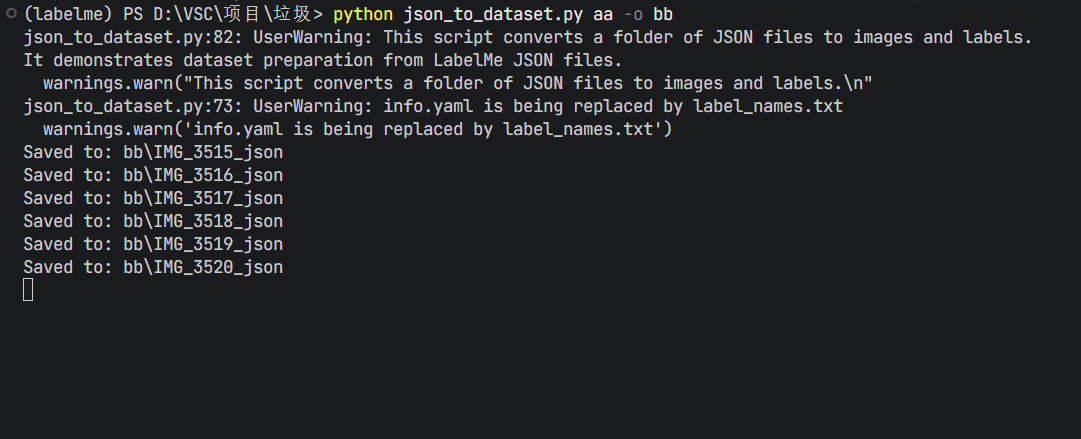
执行后,它会生成下列文件:
- img.png # 原始图片
- label.png # 标注标签图(每个像素对应类别 ID)
- label_viz.png # 可视化标签图(彩色)
- label_names.txt # 标签名称列表
- info.yaml # YAML 格式的标签信息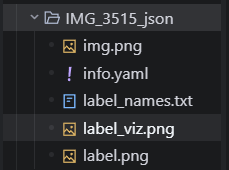
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 Vincent Cassano