
机器学习项目:基于 YOLO11的军用飞机识别
YOLO介绍
YOLO(You Only Look Once)是一种基于深度学习的实时目标检测算法,最早由 Joseph Redmon 等人提出,其主要特点是将目标检测任务转化为一个单一的回归问题,在一次前向传播中同时预测多个边界框和类别概率,因此得名 “只看一次”。这种设计使得YOLO能够实现快速且高效的目标检测,特别适合于需要实时处理的场景,如视频监控、自动驾驶等。
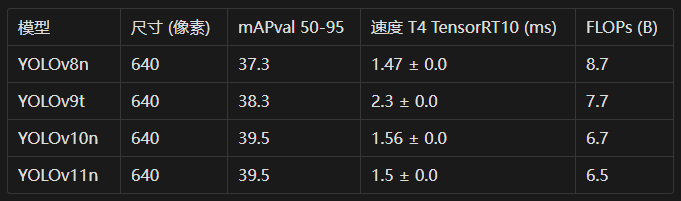
YOLOv11性能评估
项目文件夹最终分布
YOLO11_TEST2
│
├── archive # 数据集
│ ├── Annotations # xml数据文件夹
│ ├── JPEGImages # 图像文件夹
│ ├── labels # txt数据文件夹
│ └── classes.txt # 类别文件
│
├── runs # 存放训练输出的文件夹
│ └── detect
│ └── train # 训练输出文件夹
│ ├── weights # 权重文件夹,存放训练过程中保存的模型权重
│ │ ├── best.pt # 最佳权重文件
│ │ └── last.pt # 最后一次训练的权重文件
│ └── ...
│
├── test # 测试集文件夹
│ ├── test
│ │ ├── images # 测试图像
│ │ └── labels # 测试集标签
│ ├── train
│ │ ├── images
│ │ ├── labels
│ │ └── labels.cache # 标签缓存文件
│ ├── val # 验证集文件夹
│ │ ├── images
│ │ ├── labels
│ │ └── labels.cache # 标签缓存文件
│ └── data.yaml # 数据集配置文件
│
├── 0Shi_Bie_Lei_Bie.py
├── 1Geng_Gai_Ge_Shi.py
├── 2Hua_Fen_Xun_Lian_Ji.py
├── 3Mo_Xin_Xun_Lian.py
├── 4Mo_Xin_Yan_Zheng.py
├── 5Ping_Mu_Nei_Rong_Jian_Ce.py
├── pytest.py
├── test.jpg
└── yolo11n.pt # 预训练 YOLO 模型权重文件一、环境准备
Anaconda
介绍
Anaconda 是一个数据科学和机器学习的软件套装,它包含了许多工具和库,让您能够更轻松地进行编程、分析数据和构建机器学习模型。
Anaconda 包及其依赖项和环境的管理工具为conda命令,文章后面部分会详细介绍。
与传统的Python pip工具相比 Anaconda 的conda可以更方便地在不同环境之间进行切换,环境管理较为简单。
为什么选择 Anaconda?
方便安装、包管理器、环境管理、集成工具和库;
Jupyter 笔记本、Spyder 集成开发环境、跨平台性、社区支持。
安装Anaconda:
双击程序 → Next → I Agree → Next → Next → 全选 → Install → Next → Next → Finish
创建yolov11虚拟环境
#创建新的虚拟环境
conda create -n yolov11 python=3.13
#激活虚拟环境
conda activate yolov11二、yolov11模型下载
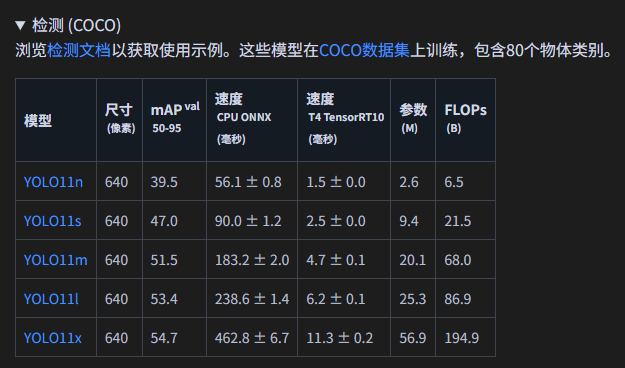
YOLO11 是UltralyticsYOLO 是实时物体检测器系列中的最新产品,以最先进的精度、速度和效率重新定义了可能实现的目标。在之前YOLO 版本令人印象深刻的进步基础上,YOLO11 在架构和训练方法上进行了重大改进,使其成为广泛的计算机视觉任务的多功能选择。
下载项目所需的python库
pip install ultralytics opencv-python mss pyyaml numpy -i https://pypi.tuna.tsinghua.edu.cn/simple/
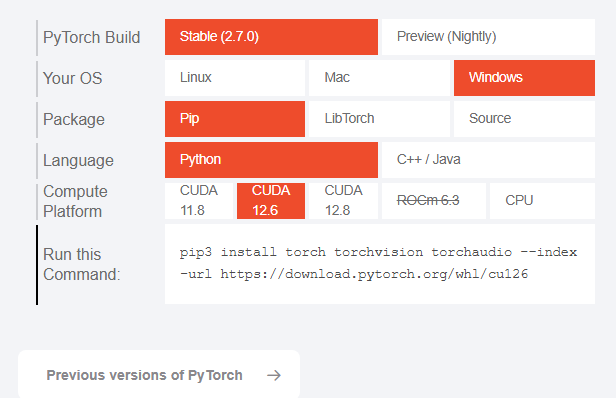
#安装GPU训练所需的python库,如果不用GPU则不用下载
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126这里的GPU所需的cu版本需要自行检查,看自己的显卡是否支持此版本
#cmd中输入
nvcc --version
nvidia-smi请注意cu126不支持python3.8之前的版本
三、准备数据集
下载现成的标注好的数据集(这个数据集比较差,因为是卫星拍摄,许多图片很模糊,建议自行筛选)
整理数据集中的类别
Python程序代码:
# 0Shi_Bie_Lei_Bie.py
import os
import xml.etree.ElementTree as ET
def extract_classes(xml_dir):
classes = set()
for file in os.listdir(xml_dir):
if not file.endswith(".xml"):
continue
path = os.path.join(xml_dir, file)
tree = ET.parse(path)
root = tree.getroot()
for obj in root.iter("object"):
cls = obj.find("name").text.strip()
classes.add(cls)
return sorted(classes)
if __name__ == "__main__":
current_path = os.path.dirname(__file__)
xml_dir = rf"{current_path}\archive\Annotations"
class_list = extract_classes(xml_dir)
# 输出到终端
print("发现的类别:", class_list)
# 保存到 classes.txt
save_path = rf"{current_path}\archive"
os.makedirs(save_path, exist_ok=True)
with open(os.path.join(save_path, "classes.txt"), "w") as f:
for cls in class_list:
f.write(cls + "\n")
labels_path = rf"{current_path}\archive\labels"
os.makedirs(labels_path, exist_ok=True)
print(f"已创建 labels 文件夹:{labels_path}")
test_path = rf"{current_path}\test"
os.makedirs(test_path, exist_ok=True)
print(f"已创建 test 文件夹:{test_path}")将xml转成txt文件
将标注文件转换为YOLO格式。YOLO格式的标注文件内容如下:
<class_id> <x_center> <y_center> <width> <height>
<类别编号> <边框中心点x坐标> <边框中心点y坐标> <边框宽度> <边框高度>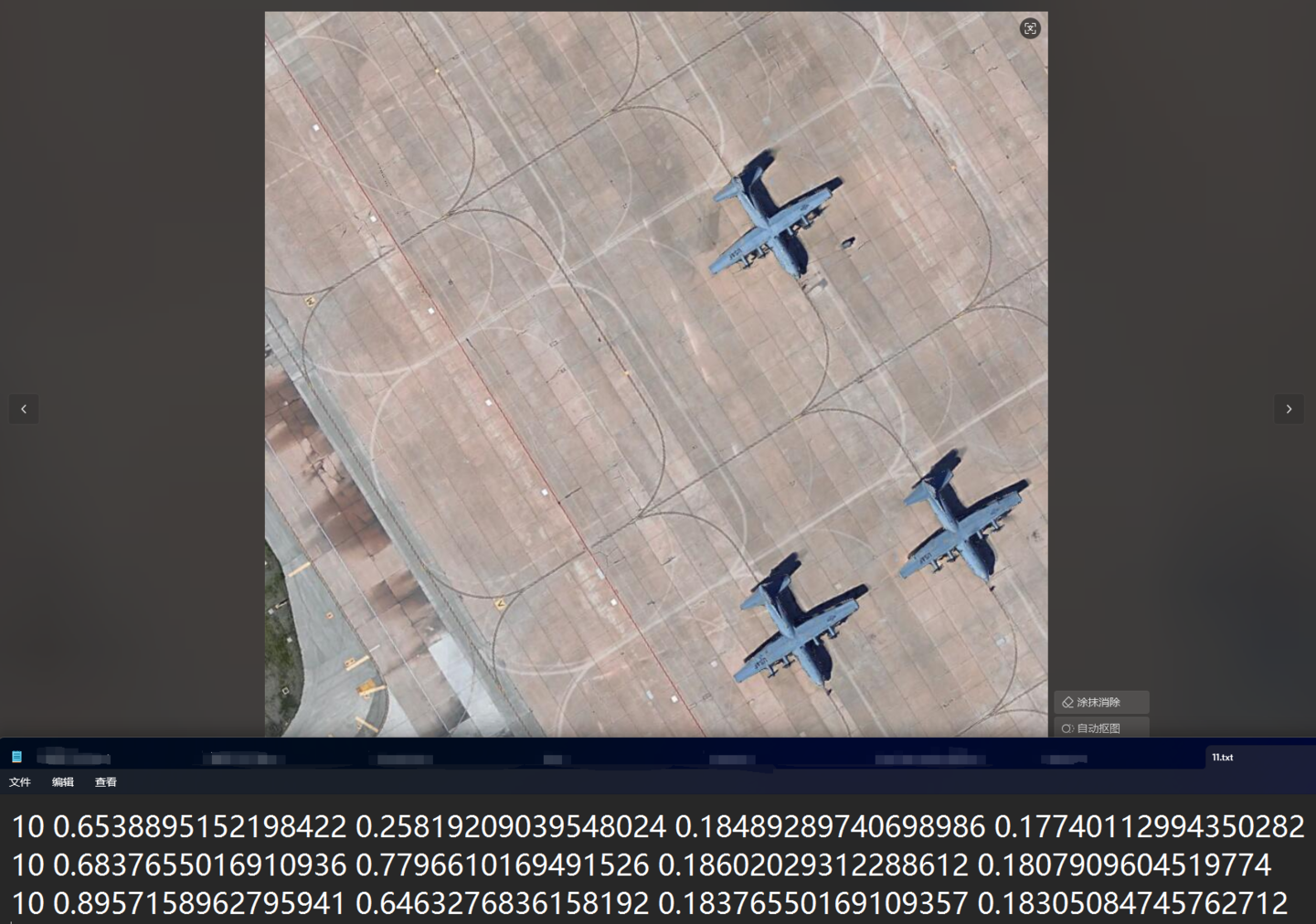
Python程序代码:
# 1Geng_Gai_Ge_Shi.py
import xml.etree.ElementTree as ET
import os
def convert(size, box):
x_center = (box[0] + box[1]) / 2.0
y_center = (box[2] + box[3]) / 2.0
x = x_center / size[0]
y = y_center / size[1]
w = (box[1] - box[0]) / size[0]
h = (box[3] - box[2]) / size[1]
return (x, y, w, h)
def convert_annotation(xml_files_path, save_txt_files_path, classes):
os.makedirs(save_txt_files_path, exist_ok=True)
xml_files = os.listdir(xml_files_path)
print(xml_files)
for xml_name in xml_files:
if not xml_name.endswith('.xml'):
continue
print(xml_name)
xml_file = os.path.join(xml_files_path, xml_name)
out_txt_path = os.path.join(save_txt_files_path, xml_name.split('.')[0] + '.txt')
out_txt_f = open(out_txt_path, 'w')
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
if w == 0 or h == 0:
print(f"[跳过] {xml_file} 图像宽或高为0")
continue
for obj in root.iter('object'):
cls = obj.find('name').text.strip()
difficult_node = obj.find('difficult')
difficult = int(difficult_node.text) if difficult_node is not None else 0
if cls not in classes or difficult == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
print(w, h, b)
bb = convert((w, h), b)
out_txt_f.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
out_txt_f.close()
if __name__ == "__main__":
current_path = os.path.dirname(__file__)
print("当前文件的路径:", current_path)
classes1 = ['A10', 'A11', 'A12', 'A13', 'A14', 'A15', 'A16', 'A18', 'A2', 'A3', 'A4', 'A5', 'A7', 'A8', 'A9'] # 请替换为你的真实类别列表
xml_files1 = rf'{current_path}\archive\Annotations'
save_txt_files1 = rf'{current_path}\archive\labels'
convert_annotation(xml_files1, save_txt_files1, classes1)
with open(save_txt_files1 + '/classes.txt', 'w') as file:
for class_name in classes1:
file.write(class_name + '\n')划分数据集
在机器学习和计算机视觉领域,特别是在深度学习模型的训练过程中,通常会将数据集划分为几个部分,以确保模型的有效性和泛化能力。这四个部分:test、train、trainval、val,各自扮演不同的角色:
Python程序代码:
# 2Hua_Fen_Xun_Lian_Ji.py
import os
import random
import shutil
import time
import yaml
class YOLOTrainDataSetGenerator:
def __init__(self, origin_dataset_dir, train_dataset_dir, train_ratio=0.7, val_ratio=0.15, test_ratio=0.15,
clear_train_dir=False):
# 设置随机数种子
random.seed(1233)
self.origin_dataset_dir = origin_dataset_dir
self.train_dataset_dir = train_dataset_dir
self.train_ratio = train_ratio
self.val_ratio = val_ratio
self.test_ratio = test_ratio
self.clear_train_dir = clear_train_dir
assert self.train_ratio > 0.5, 'train_ratio must larger than 0.5'
assert self.val_ratio > 0.01, 'train_ratio must larger than 0.01'
assert self.test_ratio > 0.01, 'test_ratio must larger than 0.01'
total_ratio = round(self.train_ratio + self.val_ratio + self.test_ratio)
assert total_ratio == 1.0, 'train_ratio + val_ratio + test_ratio must equal 1.0'
def generate(self):
time_start = time.time()
# 原始数据集的图像目录,标签目录,和类别文件路径
origin_image_dir = os.path.join(self.origin_dataset_dir, 'JPEGImages')
origin_label_dir = os.path.join(self.origin_dataset_dir, 'labels')
origin_classes_file = os.path.join(self.origin_dataset_dir, 'classes.txt')
if not os.path.exists(origin_classes_file):
return
else:
origin_classes = {}
with open(origin_classes_file, mode='r') as f:
for cls_id, cls_name in enumerate(f.readlines()):
cls_name = cls_name.strip()
if cls_name != '':
origin_classes[cls_id] = cls_name
# 获取所有原始图像文件名(包括后缀名)
origin_image_filenames = os.listdir(origin_image_dir)
# 随机打乱文件名列表
random.shuffle(origin_image_filenames)
# 计算训练集、验证集和测试集的数量
total_count = len(origin_image_filenames)
train_count = int(total_count * self.train_ratio)
val_count = int(total_count * self.val_ratio)
test_count = total_count - train_count - val_count
# 定义训练集文件夹路径
if self.clear_train_dir and os.path.exists(self.train_dataset_dir):
shutil.rmtree(self.train_dataset_dir, ignore_errors=True)
train_dir = os.path.join(self.train_dataset_dir, 'train')
val_dir = os.path.join(self.train_dataset_dir, 'val')
test_dir = os.path.join(self.train_dataset_dir, 'test')
train_image_dir = os.path.join(train_dir, 'images')
train_label_dir = os.path.join(train_dir, 'labels')
val_image_dir = os.path.join(val_dir, 'images')
val_label_dir = os.path.join(val_dir, 'labels')
test_image_dir = os.path.join(test_dir, 'images')
test_label_dir = os.path.join(test_dir, 'labels')
# 创建训练集输出文件夹
os.makedirs(train_image_dir, exist_ok=True)
os.makedirs(train_label_dir, exist_ok=True)
os.makedirs(val_image_dir, exist_ok=True)
os.makedirs(val_label_dir, exist_ok=True)
os.makedirs(test_image_dir, exist_ok=True)
os.makedirs(test_label_dir, exist_ok=True)
# 将图像和标签文件按设定的ratio划分到训练集,验证集,测试集中
for i, filename in enumerate(origin_image_filenames):
if i < train_count:
output_image_dir = train_image_dir
output_label_dir = train_label_dir
elif i < train_count + val_count:
output_image_dir = val_image_dir
output_label_dir = val_label_dir
else:
output_image_dir = test_image_dir
output_label_dir = test_label_dir
src_img_name_no_ext = os.path.splitext(filename)[0]
src_image_path = os.path.join(origin_image_dir, filename)
src_label_path = os.path.join(origin_label_dir, src_img_name_no_ext + '.txt')
if os.path.exists(src_label_path):
# 复制图像文件
dst_image_path = os.path.join(output_image_dir, filename)
shutil.copy(src_image_path, dst_image_path)
# 复制标签文件
src_label_path = os.path.join(origin_label_dir, src_img_name_no_ext + '.txt')
dst_label_path = os.path.join(output_label_dir, src_img_name_no_ext + '.txt')
shutil.copy(src_label_path, dst_label_path)
else:
pass
train_dir = os.path.normpath(train_dir)
val_dir = os.path.normpath(val_dir)
test_dir = os.path.normpath(test_dir)
data_dict = {
'train': train_dir,
'val': val_dir,
'test': test_dir,
'nc': len(origin_classes),
'names': origin_classes
}
yaml_file_path = os.path.normpath(os.path.join(self.train_dataset_dir, 'data.yaml'))
with open(yaml_file_path, mode='w') as f:
yaml.safe_dump(data_dict, f, default_flow_style=False, allow_unicode=True)
if __name__ == '__main__':
current_path = os.path.dirname(__file__)
print("当前文件的路径:", current_path)
g_origin_dataset_dir = rf'{current_path}\archive'
g_train_dataset_dir = rf'{current_path}\test'
g_train_ratio = 0.7
g_val_ratio = 0.15
g_test_ratio = 0.15
yolo_generator = YOLOTrainDataSetGenerator(g_origin_dataset_dir, g_train_dataset_dir, g_train_ratio, g_val_ratio,
g_test_ratio, True)
yolo_generator.generate()
print("任务完成")
四、模型训练
Python程序代码GPU版本:
# 3Mo_Xin_Xun_Lian.py
# coding:utf-8
from ultralytics import YOLO
import torch
import os
torch.cuda.empty_cache()
# 确保 CUDA 可用
assert torch.cuda.is_available(), "CUDA 不可用,请检查你的 GPU 驱动或 PyTorch 安装是否支持 CUDA"
# 加载 YOLOv8 模型
model = YOLO("yolo11n.pt") # 你可以改成 yolov11s.pt, yolov11m.pt, yolov11l.pt 以使用更大模型
if __name__ == '__main__':
current_path = os.path.dirname(__file__)
print("当前文件的路径:", current_path)
# 训练模型
results = model.train(
data=rf'{current_path}\test\data.yaml', # 数据集配置
epochs=300, # 训练轮数
batch=4, # 批量大小,根据你显卡显存适当调整
device='cuda', # 使用 GPU
)Python程序代码CPU版本:
# 3Mo_Xin_Xun_Lian.py
# coding:utf-8
from ultralytics import YOLO
import os
# 加载 YOLOv8 模型
model = YOLO("yolo11n.pt") # 你可以改成 yolov11s.pt, yolov11m.pt, yolov11l.pt 以使用更大模型
if __name__ == '__main__':
current_path = os.path.dirname(__file__)
print("当前文件的路径:", current_path)
# 训练模型
results = model.train(
data=rf'{current_path}\test\data.yaml', # 数据集配置
epochs=180, # 训练轮数
batch=2, # 批量大小,根据你的CPU适当调整
)CPU与GPU训练过程截图:
CPU:

GPU:
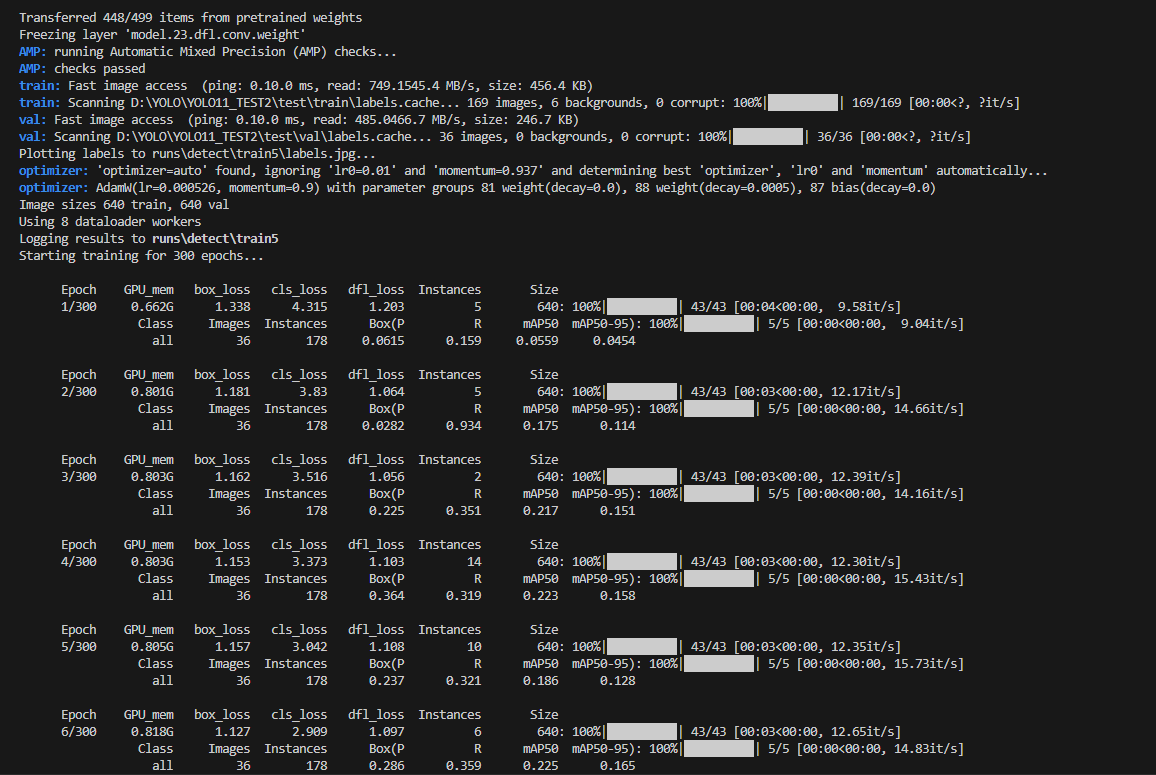
五、训练结果
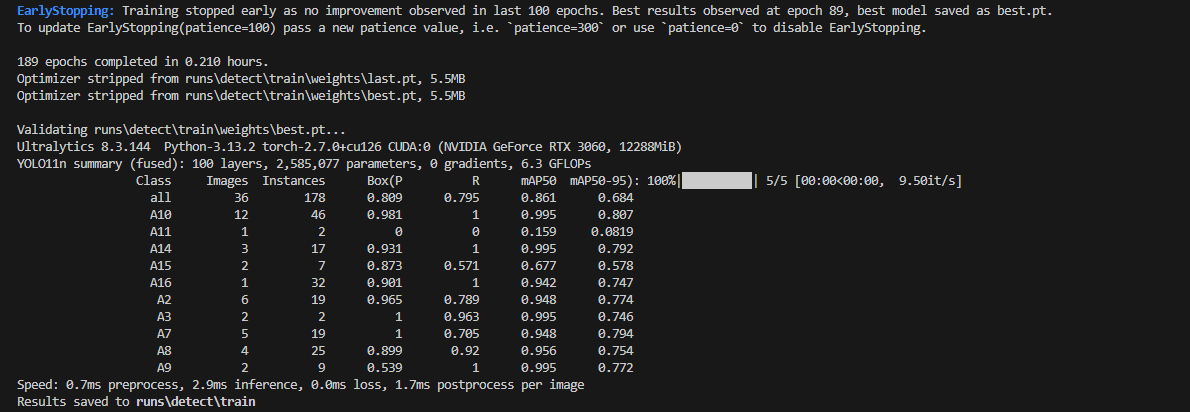
Yolov8在训练完成之后,会在runs/detect/train目录下把训练的过程一些参数与结果示意图保存下来,这里面包含是目标检测性能指标。
runs/detect/train/weights包含best.pt以及last.pt,前者是模型在验证集上表现最好的权重文件,后者是模型在训练结束时的最终权重文件,代表模型训练过程中的最后一个状态。
六、模型效果验证
对图片进行验证
Python程序代码CPU版本:
# 4Mo_Xin_Yan_Zheng.py
from ultralytics import YOLO
import os
current_path = os.path.dirname(__file__)
print("当前文件的路径:", current_path)
model = YOLO(rf'{current_path}\runs\detect\train\weights\best.pt')
if __name__ == '__main__':
results = model.predict(source='test.jpg')
results[0].show()结果:

对屏幕内容进行验证
Python程序代码CPU版本:
# 5Ping_Mu_Nei_Rong_Jian_Ce.py
import cv2
import numpy as np
from mss import mss
from ultralytics import YOLO
import os
current_path = os.path.dirname(__file__)
print("当前文件的路径:", current_path)
# 加载训练好的 YOLO 模型
model = YOLO(rf'{current_path}\runs\detect\train\weights\best.pt')
sct = mss()
# 假设屏幕分辨率为 1920x1080
screen_width = 1920
screen_height = 1080
# 捕获屏幕中央 800x600 的区域
monitor = {
"top": (screen_height - 1060) // 2, # 从屏幕中央向下偏移 230 像素
"left": (screen_width - 1400) // 2, # 从屏幕中央向左偏移 320 像素
"width": 1600, # 区域宽度
"height": 1400 # 区域高度
}
# 定义 OpenCV 窗口名称
window_name = "YOLO Detection"
if __name__ == '__main__':
try:
while True:
screenshot = sct.grab(monitor) # 捕获屏幕
img = np.array(screenshot) # 将屏幕截图转换为 numpy 数组格式 (cv2 兼容)
img = cv2.cvtColor(img, cv2.COLOR_BGRA2RGB) # 将图像从 BGRA 转换为 RGB 格式(因为 mss 捕获的图像带有 alpha 通道)
results = model.predict(source=img, show=False) # 使用 YOLO 模型对屏幕截图进行预测;禁用自动显示
result_img = results[0].plot() # 获取预测结果图像
cv2.imshow(window_name, result_img) # 显示结果图像
# 按下 'q' 键退出循环
if cv2.waitKey(1) & 0xFF == ord('q'):
break
except Exception as e:
print(f"发生错误: {e}")
finally:
# 释放资源
cv2.destroyAllWindows()